Introducing Wrynx Latent Space Probes: Real-Time Concept Detection Inside Large Language Models
As large language models are deployed in increasingly sensitive and high-stakes environments, ensuring their safety, reliability, and alignment has become a core challenge.
Most current safety systems rely on external guard models or post-generation filters. While somewhat effective, these approaches introduce significant latency, cost, and architectural complexity.
At Wrynx, we believe safety should be built into the model’s internal reasoning process—not bolted on afterward.
Today, we’re introducing Wrynx Latent Space Probes: a lightweight, high-performance framework for detecting semantic concepts directly from a model’s internal activations at runtime.
What Are Latent Space Probes?
Modern language models represent information in high-dimensional latent spaces. During inference, each layer produces activation patterns that encode:
- Intent
- Topic
- Risk signals
- Reasoning state
- Safety-relevant features
- Other conceptual features
Latent space probes are small, specialized classifiers trained to read these internal signals.
Instead of analyzing generated text, they answer questions like:
“Does this activation pattern correspond to harmful intent?”
“Is the model reasoning about prohibited content?”
“Is a sensitive domain being activated?”
All before the final output is produced.
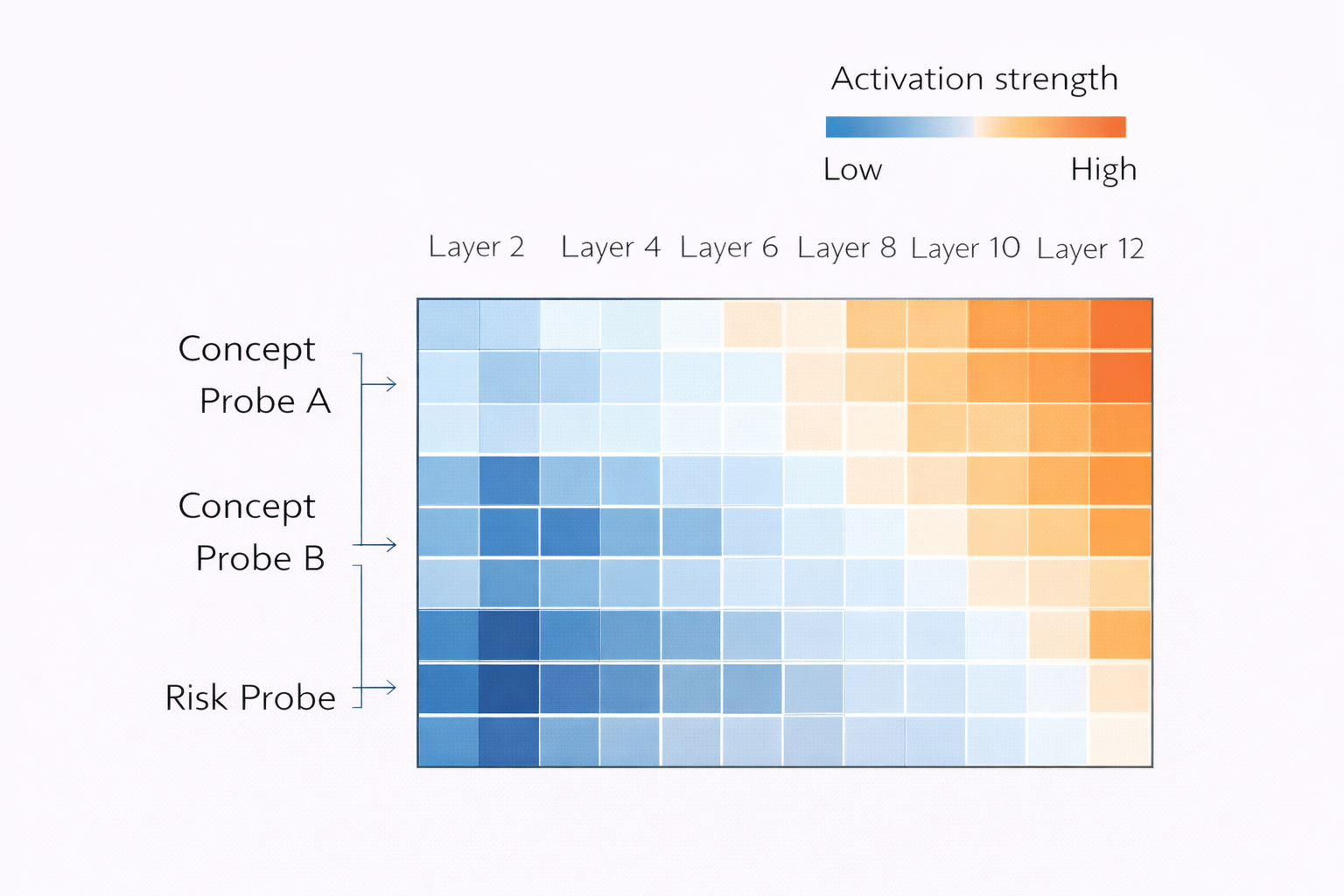
How Wrynx Probes Work
Wrynx probes are designed to be:
- Model-integrated – Attached to intermediate layers
- Lightweight – Minimal additional compute (<0.5% parameter overhead)
- Composable – Multiple probes can run in parallel
- Low-latency – No additional network calls to guard models (0.3-0.8ms addition to inference)
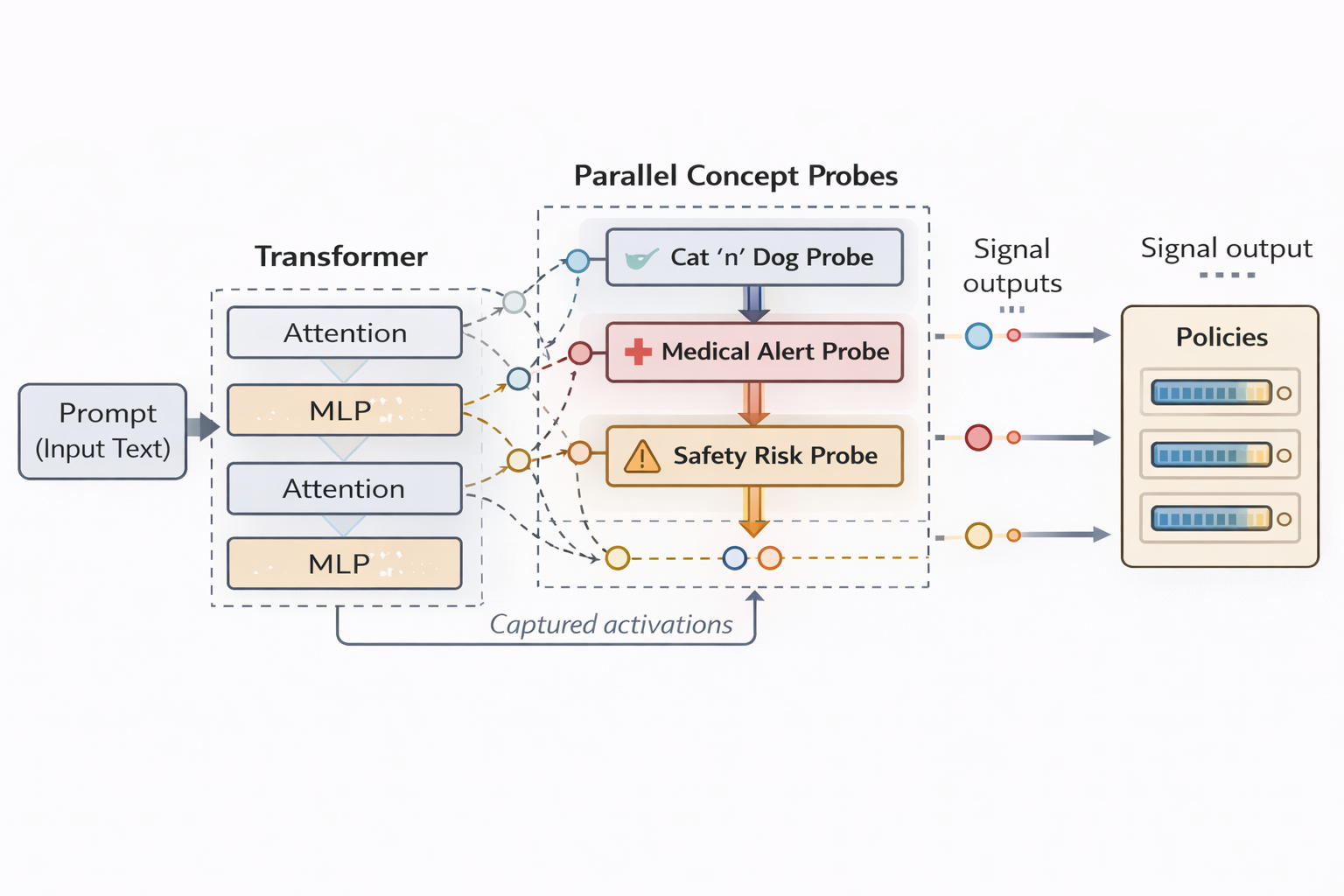
At runtime, the process looks like this:
- The LLM processes the prompt
- Activations are captured at selected layers
- Probes run alongside inference to analyze these activations
- Risk or concept signals are produced in real time
- Policies can intervene if needed
- Risk / policy scores are returned to the user as needed.
This enables early detection and intervention—often before unsafe content is fully formed.
Case Study: Safety Probing on Llama 3.1
To evaluate our approach, we conducted a case study using Llama 3.1.
Objective
We aimed to detect safety-relevant concepts such as:
- Harmful intent
- Policy violations
- Abuse-related content
- Self-harm indicators
- Disallowed instructions
Methodology
We:
- Collected labeled datasets across multiple safety domains
- Extracted intermediate activations from Llama 3.1
- Trained probes on selected layers
- Evaluated performance on held-out benchmarks
- Measured latency and cost in production-like settings
Probes were attached without modifying the base model weights.
Results
Detection Performance
Wrynx probes achieved performance comparable to strong external guard models across major safety categories:
- Precision and recall within 1–3% of guard LLMs
- Stable across prompt styles and adversarial phrasing
- Robust to paraphrasing and obfuscation
Latency
| Method | Avg Latency |
|---|---|
| External Guard LLM | ~300-500 ms |
| Prompt Text Classifier | ~300 ms |
| Wrynx Probe | ~0.5ms |
This represents approximately 1000× lower latency than external guard models.
Cost
Because probes run inside the main inference graph:
- No additional token generation
- No second model call
- No parallel infrastructure
In practice, we observed ~1000× lower cost per request compared to guard LLM pipelines.
Why Internal Probing Matters
1. Earlier Detection
Post-hoc systems only see final text. Probes observe the model’s internal reasoning trajectory, enabling:
- Earlier warnings
- More reliable classification
- Reduced evasion
2. Reduced Attack Surface
External filters are vulnerable to prompt injection and output manipulation. Internal probes operate below the prompt-output interface.
3. Production Scalability
Lower latency and cost make it feasible to deploy comprehensive safety monitoring at scale—without degrading user experience.
4. Interpretability
Activation-level signals provide insight into:
- When risk emerges
- Which layers encode sensitive concepts
- How reasoning evolves
This supports debugging, auditing, and governance.
Beyond Safety: General Concept Detection
While this case study focuses on safety, latent probes are a general-purpose tool.
They can be used for:
- Compliance monitoring
- IP protection
- Topic detection and conversation steering
- Hallucination risk
- Reasoning quality assessment
- Domain awareness
Any concept that manifests in latent space can be measured.
Looking Forward
Wrynx Latent Space Probes represent a shift toward native AI governance infrastructure—where safety, compliance, and oversight are embedded directly into model execution.
We’re currently expanding support across:
- Open-weight models
- Hosted APIs
- Multimodal systems
- Custom enterprise deployments
Our goal is to make internal monitoring as standard as logging or metrics.
Get Involved
If you’re deploying large language models in high-stakes environments and want:
- Real-time safety
- Minimal overhead
- Deep visibility
- Production-ready tooling
We’d love to work with you.
📩 Contact us at contact@wrynx.com
🌐 Learn more at wrynx.com
Wrynx — Democratizing AI models' latent space.