•Wrynx Team
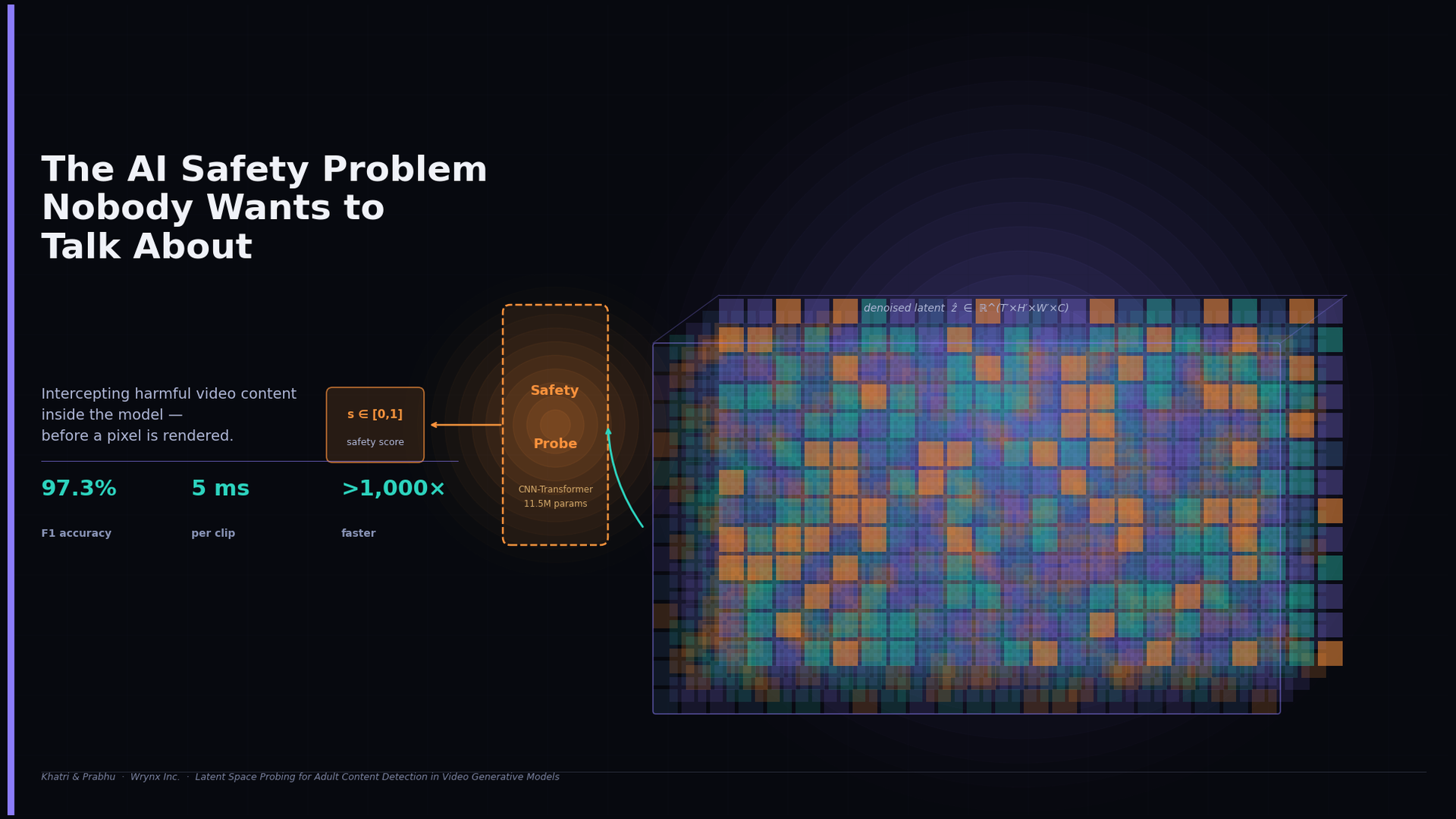
The AI Safety Problem Nobody Wants to Talk About
AI video generators can produce harmful content as easily as legitimate video. Current safety tools wait until the video is fully rendered before checking it — wasting compute and discarding the richest signal available. We took a different approach: intercepting the model's own internal representation before a single pixel is decoded. Our lightweight probe achieves 97.3% F1 accuracy at just 5ms per clip — over 1,000× faster than pixel-space baselines — with a fraction of the parameters. Safety doesn't have to be expensive. Sometimes the answer is already inside the model.
AI Safety
Read More