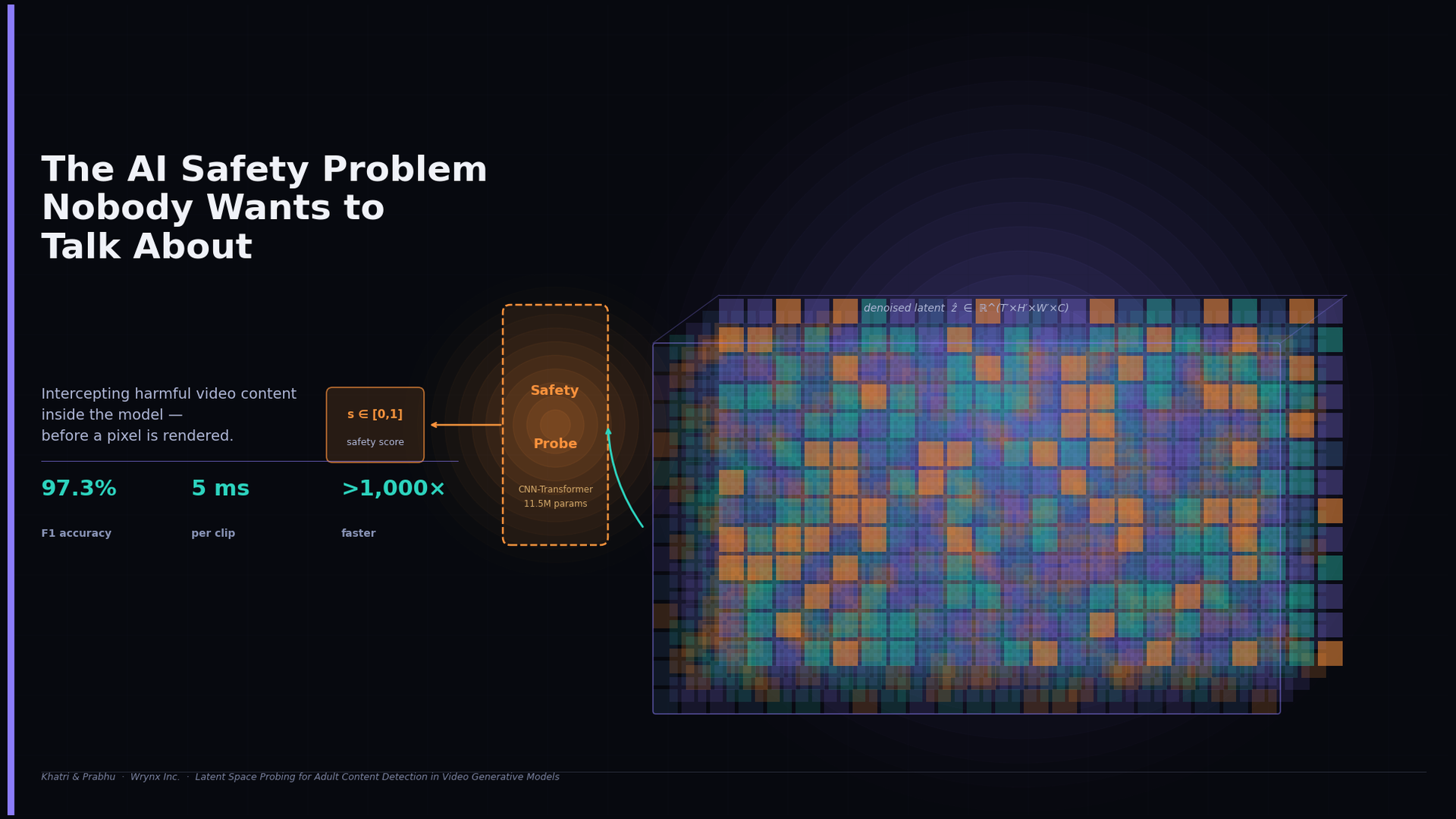
The AI Safety Problem Nobody Wants to Talk About
Somewhere right now, someone is typing a prompt into an AI video generator. Maybe it's a filmmaker testing a scene concept, a marketer prototyping an ad, or a student experimenting with a new tool. The model takes the prompt, runs it through billions of parameters, and a few seconds later produces something that looks like real video.
That same pipeline — the exact same weights, the exact same inference code — can be coaxed into producing sexually explicit material, non-consensual deepfakes, or worse. The barrier is not technical sophistication. It is often just knowing the right phrasing.
This is not a hypothetical concern. As video generation models become cheaper, faster, and more accessible, the misuse surface grows in direct proportion. The question of how platforms and developers moderate these outputs in real time is one of the most urgent and least glamorous problems in applied AI safety — and it is the problem we set out to address.
How the Industry Is Currently Failing
The dominant approach to content moderation in video generation pipelines today is embarrassingly blunt. It works like this: generate the video, decode it into pixel frames, run a classifier over those frames, and block the result if it fails. Call this post-hoc pixel-space filtering.
This strategy has two deep structural flaws.
The first is cost. Video generation is expensive. Running a 3D diffusion model for dozens of denoising steps is computationally intensive. Decoding the resulting latent tensor back into a full-resolution video multiplies that cost. Then running a separate vision classifier — typically a large model in its own right — over every frame of that video multiplies it again. And if the video is eventually blocked, every single one of those operations was wasted.
The second flaw is more subtle but more damaging: the approach throws away the most informative signal available. A video diffusion model does not work by randomly assembling pixels. It works by building up a rich, semantically organized internal representation of the scene it is generating — a compressed encoding that captures what the video means, not just what it looks like. By waiting until the video has been decoded to pixels before making a safety judgment, current approaches discard exactly the representation that the model itself used to understand what it was generating.
There is also a third concern, specific to prompt-based filtering: prompts can be rephrased. Indirect language, coded terms, and adversarial inputs are known to circumvent text classifiers routinely. A filter that sits at the prompt level is, by design, playing catch-up with users who are motivated to evade it.
A Different Way to Think About the Problem
Our work reorients the problem entirely. Rather than inspecting inputs or decoded outputs, we asked a simpler question: what does the model know about what it is generating, and when does it know it?
The answer, it turns out, is that the model knows a great deal — and it knows it early. By the time a video diffusion model completes its denoising process, the resulting latent tensor is not random noise. It is a compact, semantically coherent description of the video content. It has been shaped by thousands of denoising steps conditioned on a text description. If that text described explicit content, the latent representation reflects it.
Our proposal is to train a lightweight classifier — a probe — directly on this latent representation, before the expensive decode step ever runs. The probe reads the model's own internal understanding of what it has generated and returns a safety score. If the score exceeds a threshold, the decode step can be aborted entirely. The harmful video is never rendered.
Integrating with the Video Generation Pipeline
To make this concrete, we built our framework on top of CogVideoX, a 5B-parameter open-source video generation model that supports text-to-video, image-to-video, and video-to-video generation. Understanding where our probe fits requires understanding how CogVideoX processes a request.
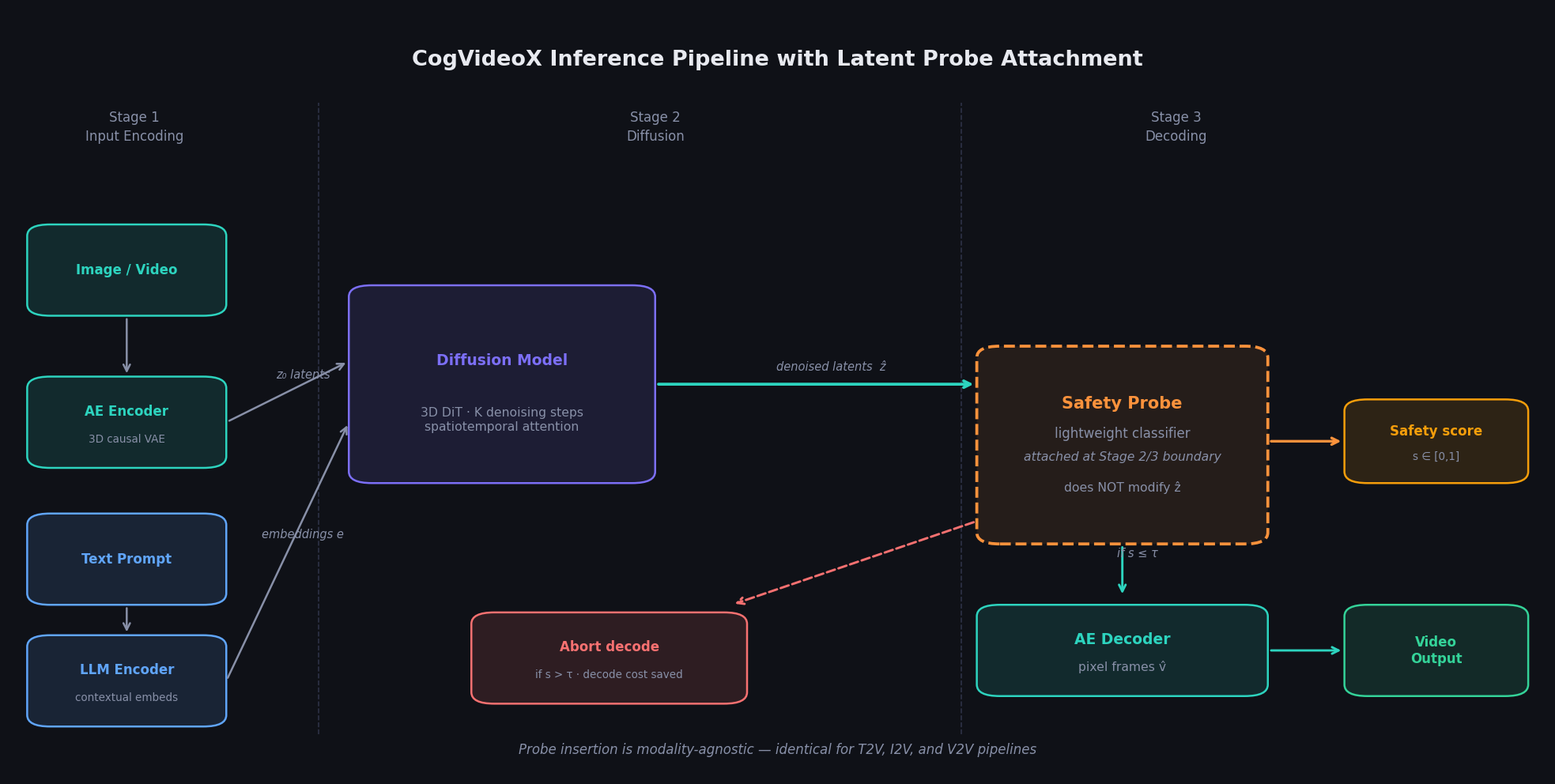
The pipeline has three stages. In Stage 1, inputs are encoded: images or videos are compressed by a 3D causal Variational Autoencoder (VAE) into a low-dimensional latent tensor z₀ ∈ R^(T'×H'×W'×C), while the text prompt is tokenized and passed through an LLM encoder to produce contextual embeddings. For a 720p clip, the VAE compresses spatially by 8× and temporally by 4×, yielding a latent of roughly T' × 90 × 160 × 16.
In Stage 2, a 3D Diffusion Transformer (DiT) iteratively denoises z₀ conditioned on the text embeddings over K steps, producing clean denoised latents ẑ. This is where the model's semantic understanding of the generated content is fully crystallized.
In Stage 3, the AE decoder maps ẑ back to full-resolution pixel frames.
We insert our probe at the boundary between Stage 2 and Stage 3. It intercepts ẑ after the final denoising step without modifying it, produces a scalar safety score s ∈ [0, 1] as a side-channel output, and returns this to the caller alongside (or instead of) the decoded video. If s exceeds a configurable threshold τ, decoding is aborted. Because our probe operates exclusively on Stage 2 outputs, it is entirely modality-agnostic: the same probe works unchanged for text-to-video, image-to-video, and video-to-video pipelines — something we verified empirically.
Building the Dataset
Before we could train any classifier, we needed labeled data. This is one of the most significant practical barriers in this field: most high-quality adult content detection datasets are proprietary, and public benchmarks are small and narrowly distributed. We decided to build our own from scratch.
Our dataset consists of 11,039 ten-second video clips, split between violating and non-violating content.
| Label | Source videos | Clips |
|---|---|---|
| Violating | 91 | 5,806 |
| Non-violating | 69 | 5,953 |
| Total | 160 | 11,039 |
Violating clips were sourced from publicly accessible legal adult content websites, spanning heterosexual, homosexual, self-pleasure, and group acts across a range of ethnicities, and including animated content. Non-violating clips came from YouTube across a broad range of categories — cooking, sports, education, news, vlogs — specifically chosen to prevent our models from learning spurious correlations between content category and safety label.
Every source video was segmented into non-overlapping 10-second clips at 24fps. Clips from violating sources were reviewed by two human annotators who confirmed the presence of explicit content; ambiguous boundary clips were retained with appropriate labels rather than discarded, improving label quality at the edges. We split the dataset 80/10/10, stratified by source video to prevent clips from the same video appearing in both training and evaluation sets — a methodological detail that matters greatly for honest performance reporting.
Our annotators were provided with clear guidelines, mental health support resources, and scheduled breaks throughout the process.
Two Probe Architectures
We designed two classifier architectures that operate directly on the denoised latent ẑ. Both accept the latent tensor with 16 channels at spatial resolution 60×90.
Architecture 1: CNN-Transformer (Primary)
Our primary architecture is a hybrid model that combines 3D convolutional feature extraction with a Transformer encoder for temporal modeling.
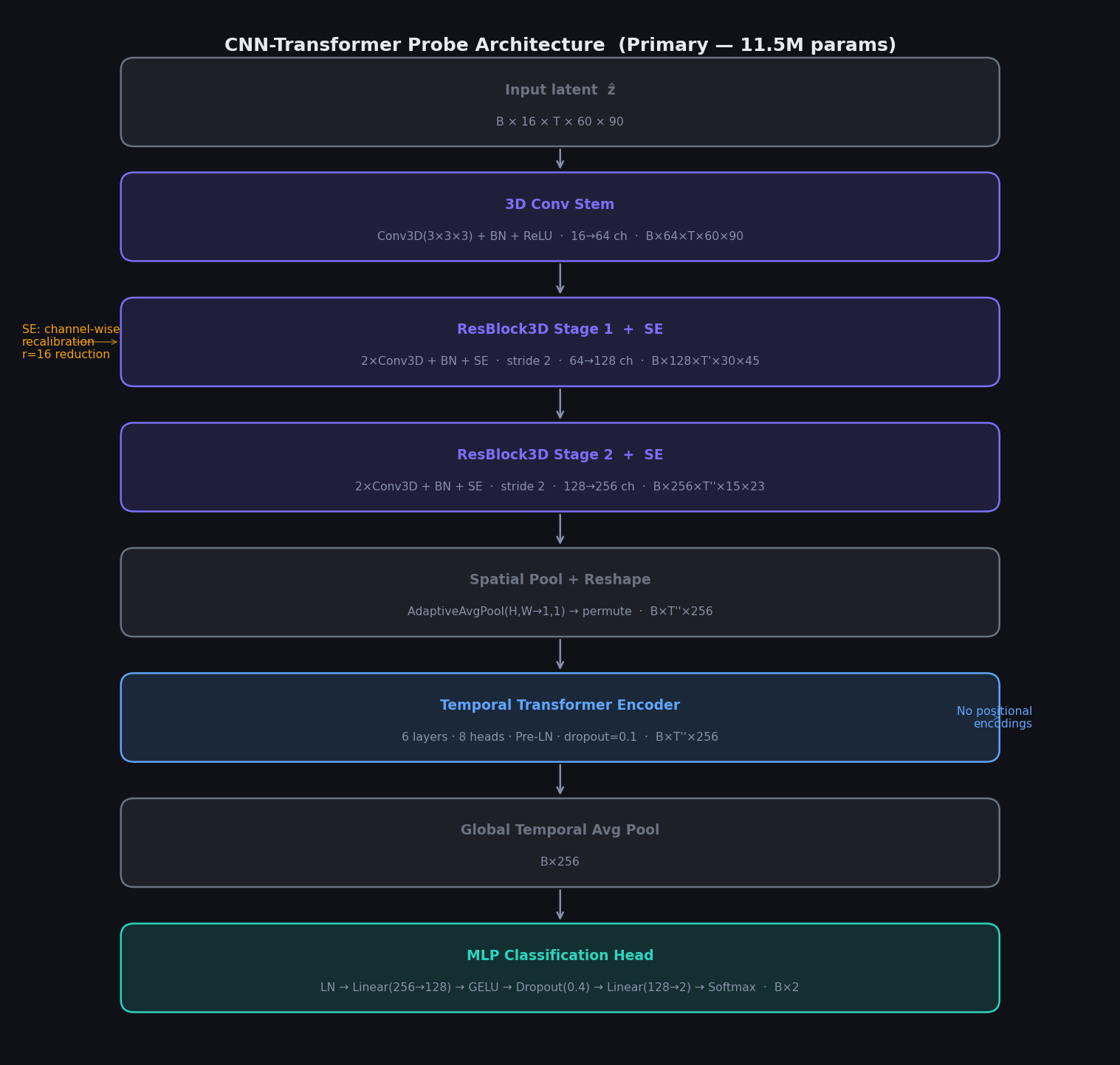
A 3D convolutional stem first projects the 16-channel input to 64 channels without any downsampling. Two 3D residual stages with Squeeze-and-Excitation (SE) recalibration then progressively increase channel depth (64→128→256) while halving the spatiotemporal resolution at each stage via stride-2 convolutions. The SE module performs channel-wise feature recalibration using a global average pool followed by a two-layer excitation network with reduction ratio r=16 — letting the network learn which channels are most predictive of content type.
After the convolutional stages, adaptive average pooling collapses the spatial dimensions, leaving a sequence of per-frame feature vectors of shape B×T''×256. This sequence is fed to a 6-layer Transformer encoder with 8 attention heads and Pre-Layer Normalization, which models temporal dependencies across the latent frames without any positional encodings. Global temporal average pooling then produces a single B×256 vector, which passes through an MLP head (LayerNorm → Linear → GELU → Dropout(0.4) → Linear → Softmax) to produce binary class probabilities.
Total parameters: ~11.5M.
Architecture 2: Vanilla 3D CNN (Baseline)
We also designed a simpler baseline: three convolutional blocks with an asymmetric first-layer kernel (3×5×5), two max-pooling stages, adaptive average pooling to 1×1×1, and a two-layer MLP head (128→64→2). No temporal attention, no residual connections, no SE recalibration.
Total parameters: ~314K — roughly 36× fewer than our transformer variant.
Training
Crucially, neither probe ever sees a decoded video frame during training. We first ran all 11,039 clips through the CogVideoX encoder and diffusion model (Stages 1 and 2 only) and stored the resulting denoised latents ẑ on disk. This one-time extraction pass decouples probe training from the generative model entirely. The resulting latent dataset occupies 1.2GB — modest by any standard.
We then trained both probes with Adam (lr = 5×10⁻³), binary cross-entropy loss, for 150 epochs on a single NVIDIA L40S 48GB GPU.
Results
The numbers exceeded our expectations.
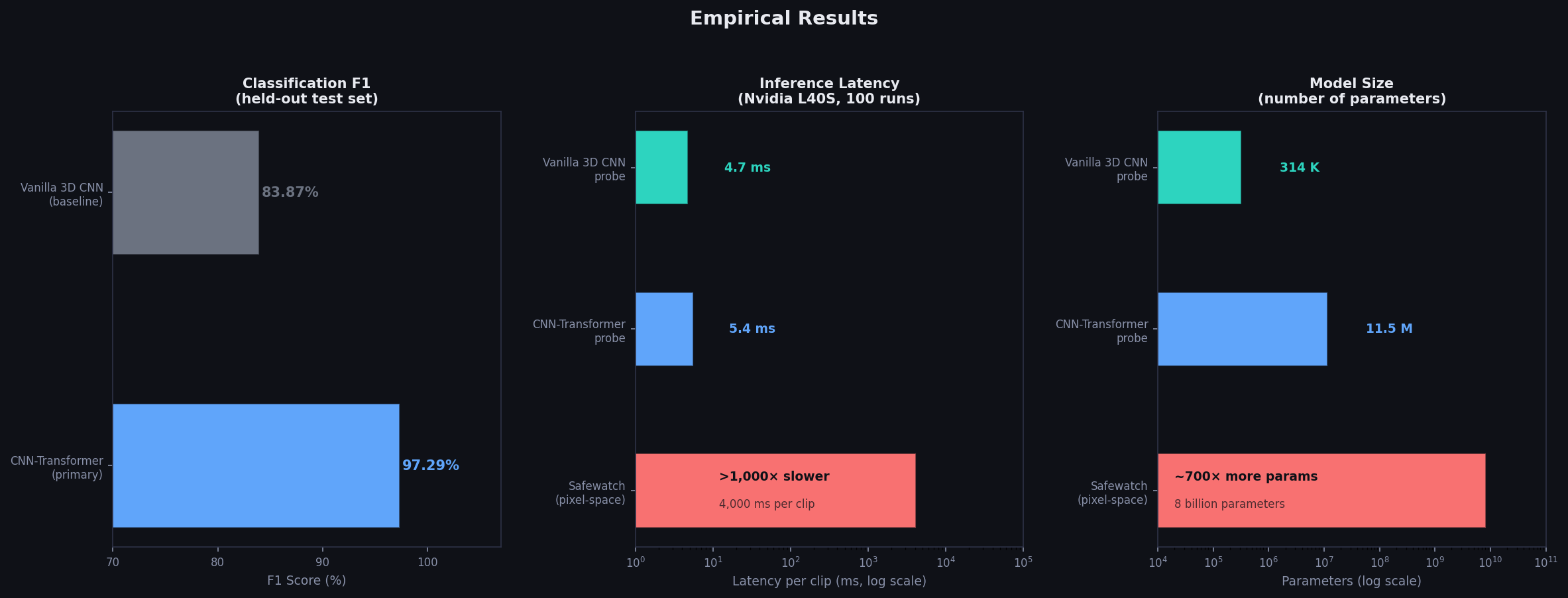
On the held-out test set, our CNN-Transformer probe achieves 97.29% F1 (98.63% precision, 95.99% recall). The vanilla 3D CNN reaches 83.87% F1 — respectable, but the gap with our transformer variant confirms that attention-based temporal modeling over the latent sequence adds meaningful signal.
More dramatically, both of our probes add 4–6 milliseconds of overhead per clip. Safewatch — an 8-billion-parameter pixel-space video guardrail model — requires 3–5 seconds per clip. That is a greater than 1,000× latency improvement, achieved while matching or exceeding its accuracy for this task.
| Probe | Precision | Recall | F1 | Latency |
|---|---|---|---|---|
| CNN-Transformer | 98.63% | 95.99% | 97.29% | 5.4ms |
| Vanilla 3D CNN | 80.53% | 87.50% | 83.87% | 4.7ms |
| Safewatch (pixel-space) | — | — | — | 3,000–5,000ms |
On model size, our transformer probe uses ~700× fewer parameters than Safewatch. We want to be careful here: Safewatch covers a broader range of harm categories, so this is not a fully apples-to-apples comparison. But the orders-of-magnitude difference in parameters, combined with competitive accuracy on the adult content detection task specifically, makes a strong case that operating in latent space is fundamentally more parameter-efficient.
Why Latent Representations Work So Well
The intuition behind our results is worth unpacking. CogVideoX's diffusion model is trained to denoise latents conditioned on textual descriptions of scene content. This means its internal representations are explicitly optimized to encode what is happening in a scene — not pixel statistics, but semantic content. Adult content is semantically describable: it is not an edge case the model has never encountered in training. It is a coherent, recognizable category that occupies a structured region of the latent space.
The strong performance of even our simpler vanilla CNN probe suggests that adult content in the latent space is not subtly distributed across thousands of dimensions in a way that requires elaborate detection machinery — it is, to a significant degree, linearly separable. Our transformer's additional gains come from better temporal modeling, but the core signal is robustly present.
We also take our results as evidence that the CogVideoX AE encoder is semantically content-preserving despite its 32× overall compression ratio. The latent space may be compressed, but it is not lossy in the ways that matter for content understanding.
What We Haven't Solved
We want to be candid about the limits of this work. Our probes are trained on latents derived from real-world videos encoded through the CogVideoX VAE. At inference time, however, they are applied to latents produced by the diffusion process itself — a slightly different distribution. This domain gap is an open issue that could affect real-world deployment accuracy.
We have also not tested our probes against adversarial attacks: a determined actor who can directly manipulate the latent space might craft inputs that fool the probe while still producing harmful decoded video. This is a meaningful threat model for production systems and something we intend to explore in future work.
Two further limitations are structural rather than technical. Our dataset uses binary labels only, but practical moderation policies often require distinguishing between nudity, explicit sexual activity, and suggestive-but-non-explicit content. And our work is specific to CogVideoX — whether our approach generalizes to other architectures like Wan or flow-matching-based models is something we have not yet tested.
We also want to flag an important ethical dimension: content moderation systems carry dual risks of under-enforcement and over-enforcement. A false positive in a generative pipeline means a legitimate creative output is suppressed. We advocate for human-in-the-loop review at borderline confidence levels, and we recognise that our binary "violating" threshold reflects conservative platform norms that may need adjustment for different cultural and jurisdictional contexts.
What We Believe This Changes
What excites us most about this work is not just the benchmark numbers. It is the underlying finding: that the most useful safety signal in a video generation pipeline is not the video itself, but the model's own internal representation of what it is generating.
If that finding holds up at scale and across model families, it has significant implications for how AI safety infrastructure gets built. Right now, safety and generation are treated as separate systems — one produces content, the other checks it after the fact. Our probing approach dissolves that separation. Safety becomes a property you read from the generation process itself, not something you bolt on afterwards.
Our work connects to a broader thread of research around using the internal states of AI models as signals for alignment, honesty, and harm detection — a line of inquiry that has shown results in language models and is now beginning to extend to multimodal generation. Video generation is a harder target than text, but the latent representations are, in some ways, richer and more spatiotemporally structured. We believe that structure has barely begun to be exploited.
The problem of unsafe video generation is not going away. We hope this work is a useful step toward addressing it.
Paper: "Latent Space Probing for Adult Content Detection in Video Generative Models" Read Full Paper